Some of my stories as seen on my defunct Storify webpage
Some digitally created content, like ill-considered tweets, seems to last forever. They come back to haunt the author at most inopportune times. But other digital content, on which precious time was spent, can disappear.
Storify, which was software that allowed tweets to be strung together, together with commentary, and other media, in order to create a longer narrative, went off-line in 2018. I used Storify to create blog posts.
Fortunately, I was aware of Storify's impending retirement, and I downloaded copies of the content that I had created. Some, but not all of of it is online again.
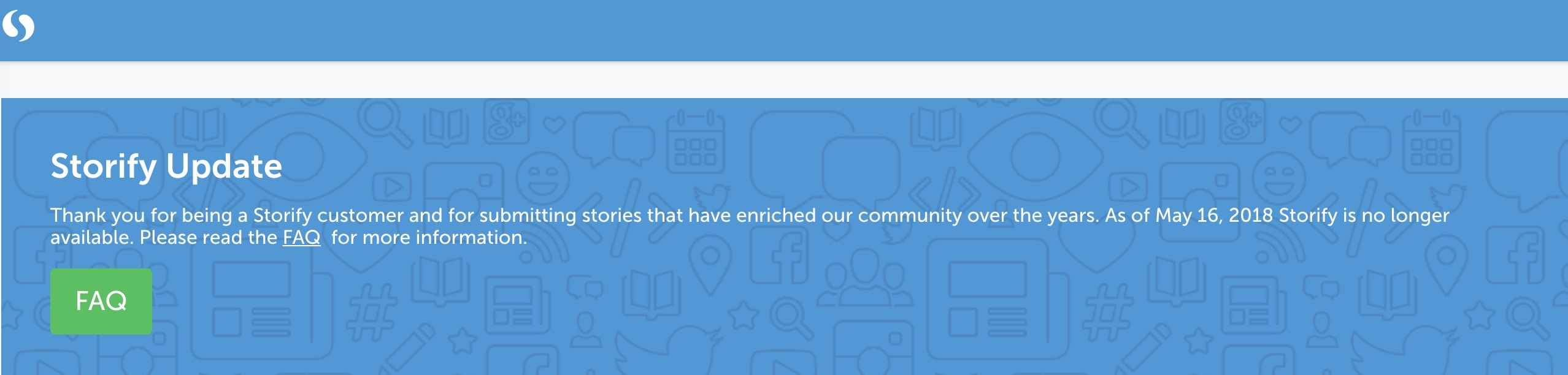

A posts that was a Storify story of strung- together tweets and commentary
Digital content and knowledge is being created at unprecedented rates, and a lot of it is also disappearing rapidly, for reasons discussed in my post on link rot. In their 2011 paper in the journal, Data Technologies and Applications, entitled Disappearing Act: Persistence and attrition of uniform resource locators (URLs) in an open access medical journal, Nagaraja et al. found that up to 17% of urls for cited references were defunct:
"In total, 1,133 articles were published from 2005‐2007 in PLoS Medicine. The 1,133 articles contained 28,177 references, with 2,503 (8.9 per cent) identified as URLs. Non‐research articles accounted for a substantially higher percentage of URL references (17.4 per cent) compared to research articles (4.2 per cent). Almost 17 per cent of the URL references were defunct and the rate of URL attrition increased as time elapsed."
Academics, researchers and students need to be aware of the rates at which knowledge and information is dying before our eyes, and to know how best to address this. It's commonplace for students to tell me "I lost my digital photo or my essay from last year. It wasn't backed up, and even though I emailed it to myself, I deleted my inbox and and it all disappeared."
In contrast, I rarely hear students and my colleagues discuss their approach to record keeping of their digitally produced content, so that if a website or company where it was posted, goes dark, like Storify, the creator or author has a copy of their content.
Institutional Repositories: part of the solution
In my experience, most academic institutions are doing a poor job of maintaining their digital histories, knowledge ecosystems and institutional memory. At York University, there has been a chronic lack of attention to, and policy development for preserving the vast amount of grey literature publications, knowledge, data and information posted on university webpages. This, despite me pointing this out to senior leadership from the late 2000s to as recently as November 2017. More on this in a future blog post.
Fortunately, most universities in the global north, including York University, have institutional repositories. These discoverable, searchable, open access digital archives aim to provide longer-lived, more stable records of digital media, such as publications.
I strongly encourage all members of academic institutions to learn how use them and to upload their academic materials. Figshare is another open access repository which hosts open access digital content but it is not affiliated with a single university, though many researchers use it as an archive. I note that Figshare is not owned by a public institution.
Recently, Dr. Lisa Buckley expressed concern about making her research and publications available on websites with stable urls.
I have a $0.00 budget for publishing. Be considerate of low resource labs, no-budget early career scis, and those scis not affiliated with an institution with a budget. https://t.co/OTNEIqMPZj
— Dr. Lisa Buckley 🦃 (@Lisavipes) October 16, 2018
I responded by asking Lisa if she had considered depositing her publications in the institutional repository of the university where she did her graduate research.
Have you gained/retained access to one of the institutional repositories at a university you are/were affiliated with?
You can deposit your work there (different versions depending on the journal status) and it’s #openaccess & discoverability is favoured in online searches.— Dawn Bazely (@dawnbazely) October 17, 2018

2013 Conference Poster about Churchill Community of Knowledge
In my experience, the Digital Librarians who lead, organize and support institutional repositories are very open to hosting documents from alumni, especially if the research was done while the person was at the university. I think that Lisa should reach out to the Digital Initiatives librarian of the university where she did her doctorate and ask for permission to upload her work to the repository, which is likely to significantly increase its visibility and discoverability.
There may also be collections to which which the information can be added, even when the researcher was not at that particular university. One such example is the Churchill Community of Knowledge Collection in YorkSpace. This archive digitizes and gathers together as much of the published research and ancillary materials as possible, done in and around Churchill, Manitoba, including Wapusk National Park, since the 1960s. The articles, photos and other digitized media in this collection, was done by students and professors from many different universities. The work is housed here rather than in those researchers' university institutional repositories, because of the theme of the collection. This decision was taken by the York University Digital Initiatives librarian in consultation with librarians at some of the other universities.

Biology research practicum student, Cheyenne, digitizes selected slides of fieldwork from the 1970s and 1980s.
My students and I have obtained permission to upload information to Yorkspace from the copyright holders. The content includes digitized Kodachrome slides of field work, accompanied by extensive metadata. Undergraduate biology students doing research practicums in this area have learned an enormous amount about digital knowledge, intellectual property and open access academic publishing.
Back in 2014, students in my lab. surveyed members of the York University science faculty community to gain insight into their knowledge of digital knowledge, open access, open source and open data. We discovered that their understanding was far from comprehensive, or even accurate, indicating that there is much education to be done.
In the meantime, since some members of the York University administrative leadership have been doing nearly as good a job as Donald Trump, of removing online knowledge, data, publications, and institutional history, I am backing up my digitally-created content, as much as possible, onto stand alone hard drives, in the cloud, on external, non-university websites and in my institutional repository.